
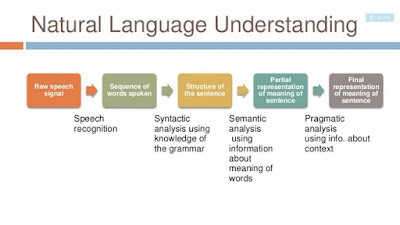
Natural language
processing (NLP) is a branch of artificial intelligence that entails mining
human text and voice in order to produce or reply to human enquiries in a
legible or natural manner.
To decode the ambiguities and opacities of genuine human
language, NLP has needed advances in statistics, machine learning, linguistics,
and semantics.
Chatbots will employ natural language processing to connect
with humans across text-based and voice-based interfaces in the future.
Interactions between people with varying talents and demands
will be supported by computer assistants.
By making search more natural, they will enable natural
language searches of huge volumes of information, such as that found on the
internet.
They may also incorporate useful ideas or nuggets of
information into a variety of circumstances, including meetings, classes, and
informal discussions.
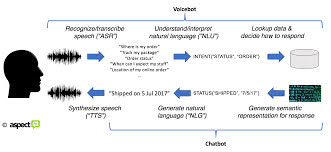
They may even be able to "read" and react in real
time to the emotions or moods of human speakers (so-called "sentient
analysis").
By 2025, the market for NLP hardware, software, and services
might be worth $20 billion per year.
Speech recognition, often known as voice recognition, has a
long history.
Harvey Fletcher, a physicist who pioneered research showing
the link between voice energy, frequency spectrum, and the perception of sound
by a listener, initiated research into automated speech recognition and
transcription at Bell Labs in the 1930s.
Most voice recognition algorithms nowadays are based on his
research.
Homer Dudley, another Bell Labs scientist, received patents
for a Vodor voice synthesizer that imitated human vocalizations and a parallel
band pass vocodor that could take sound samples and put them through narrow
band filters to identify their energy levels by 1940.
By putting the recorded energy levels through various
filters, the latter gadget might convert them back into crude approximations of
the original sounds.
Bell Labs researchers had found out how to make a system
that could do more than mimic speech by the 1950s.
During that decade, digital technology had progressed to the
point that the system could detect individual spoken word portions by comparing
their frequencies and energy levels to a digital sound reference library.
In essence, the system made an informed guess about the
expression being expressed.
The pace of change was gradual.
Bell Labs robots could distinguish around 10 syllables
uttered by a single person by the mid-1950s.
Researchers at MIT, IBM, Kyoto University, and University
College London were working on recognizing computers that employed statistics
to detect words with numerous phonemes toward the end of the decade.
Phonemes are sound units that are perceived as separate from
one another by listeners.
Additionally, progress was being made on systems that could
recognize the voice of many speakers.
Allen Newell headed the first professional automated speech
recognition group, which was founded in 1971.
The research team split their time between acoustics,
parametrics, phonemics, lexical ideas, sentence processing, and semantics,
among other levels of knowledge generation.
Some of the issues examined by the group were investigated
via funds from the Defense Advanced Research Project Agency in the 1970s
(DARPA).
DARPA was intrigued in the technology because it might be
used to handle massive amounts of spoken data generated by multiple government
departments and transform that data into insights and strategic solutions to
challenges.
Techniques like dynamic temporal warping and continuous
voice recognition have made progress.
Computer technology progressed significantly, and numerous
mainframe and minicomputer manufacturers started to perform research in natural
language processing and voice recognition.
The Speech Understanding Research (SUR) project at Carnegie
Mellon University was one of the DARPA-funded projects.
The SUR project, directed by Raj Reddy, produced numerous
groundbreaking speech recognition systems, including Hearsay, Dragon, Harpy,
and Sphinx.
Harpy is notable in that it employs the beam search
approach, which has been a standard in such systems for decades.
Beam search is a heuristic search technique that examines a
network by extending the most promising node among a small number of
possibilities.
Beam search is an improved version of best-first search that
uses less memory.
It's a greedy algorithm in the sense that it uses the
problem-solving heuristic of making the locally best decision at each step in
the hopes of obtaining a global best choice.
In general, graph search algorithms have served as the
foundation for voice recognition research for decades, just as they have in the
domains of operations research, game theory, and artificial intelligence.
By the 1980s and 1990s, data processing and algorithms had
advanced to the point where researchers could use statistical models to
identify whole strings of words, even phrases.
The Pentagon remained the field's leader, but IBM's work had
progressed to the point where the corporation was on the verge of manufacturing
a computerized voice transcription device for its corporate clients.
Bell Labs had developed sophisticated digital systems for
automatic voice dialing of telephone numbers.
Other applications that seemed to be within reach were
closed captioned transcription of television broadcasts and personal automatic
reservation systems.
The comprehension of spoken language has dramatically
improved.
The Air Travel Information System was the first commercial
system to emerge from DARPA funding (ATIS).
New obstacles arose, such as "disfluencies," or
natural pauses, corrections, casual speech, interruptions, and verbal fillers
like "oh" and "um" that organically formed from
conversational speaking.
Every Windows 95 operating system came with the Speech
Application Programming Interface (SAPI) in 1995.
SAPI (which comprised subroutine definitions, protocols, and
tools) made it easier for programmers and developers to include speech
recognition and voice synthesis into Windows programs.
Other software developers, in particular, were given the
option to construct and freely share their own speech recognition engines
thanks to SAPI.
It gave NLP technology a big boost in terms of increasing
interest and generating wider markets.
The Dragon line of voice recognition and dictation software
programs is one of the most well-known mass-market NLP solutions.
The popular Dragon NaturallySpeaking program aims to provide
automatic real-time, large-vocabulary, continuous-speech dictation with the use
of a headset or microphone.
The software took fifteen years to create and was initially
published in 1997.
It is still widely regarded as the gold standard for
personal computing today.
One hour of digitally recorded speech takes the program
roughly 4–8 hours to transcribe, although dictation on screen is virtually
instantaneous.
Similar software is packaged with voice dictation functions
in smart phones, which converts regular speech into text for usage in text
messages and emails.
The large amount of data accessible on the cloud, as well as
the development of gigantic archives of voice recordings gathered from smart
phones and electronic peripherals, have benefited industry tremendously in the
twenty-first century.
Companies have been able to enhance acoustic and linguistic
models for voice processing as a result of these massive training data sets.
To match observed and "classified" sounds,
traditional speech recognition systems employed statistical learning methods.
Since the 1990s, more Markovian and hidden Markovian systems
with reinforcement learning and pattern recognition algorithms have been used
in speech processing.
Because of the large amounts of data available for matching
and the strength of deep learning algorithms, error rates have dropped
dramatically in recent years.
Despite the fact that linguists argue that natural languages
need flexibility and context to be effectively comprehended, these
approximation approaches and probabilistic functions are exceptionally strong in
deciphering and responding to human voice inputs.
The n-gram, a continuous sequence of n elements from a given
sample of text or voice, is now the foundation of computational linguistics.
Depending on the application, the objects might be pho
nemes, syllables, letters, words, or base pairs.
N-grams are usually gathered from text or voice.
In terms of proficiency, no other method presently
outperforms this one.
For their virtual assistants, Google and Bing have indexed
the whole internet and incorporate user query data in their language models for
voice search applications.
Today's systems are starting to identify new terms from
their datasets on the fly, which is referred to as "lifelong
learning" by humans, although this is still a novel technique.
Companies working in natural language processing will desire
solutions that are portable (not reliant on distant servers), deliver
near-instantaneous response, and provide a seamless user experience in the
future.
Richard Socher, a deep learning specialist and the founder
and CEO of the artificial intelligence start-up MetaMind, is working on a
strong example of next-generation NLP.
Based on massive chunks of natural language information, the
company's technology employs a neural networking architecture and reinforcement
learning algorithms to provide responses to specific and highly broad
inquiries.
Salesforce, the digital marketing powerhouse, just purchased
the startup.
Text-to-speech analysis and advanced conversational
interfaces in automobiles will be in high demand in the future, as will speech
recognition and translation across cultures and languages, automatic speech
understanding in noisy environments like construction sites, and specialized
voice systems to control office and home automation processes and
internet-connected devices.
To work on, any of these applications to enhance human
speech will need the collection of massive data sets of natural language.
Find Jai on Twitter | LinkedIn | Instagram
You may also want to read more about Artificial Intelligence here.
See also:
Natural Language Generation; Newell, Allen; Workplace Automation.
References & Further Reading:
Chowdhury, Gobinda G. 2003. “Natural Language Processing.” Annual Review of Information Science and Technology 37: 51–89.
Jurafsky, Daniel, and James H. Martin. 2014. Speech and Language Processing. Second edition. Upper Saddle River, NJ: Pearson Prentice Hall.
Mahavan, Radhika. n.d. “Natural Language Processing: Current Applications and Future Possibilities.” https://www.techemergence.com/nlp-current-applications-and-future-possibilities/.
Manning, Christopher D., and Hinrich Schütze. 1999. Foundations of Statistical Natural Language Processing. Cambridge, MA: MIT Press.
Metz, Cade. 2015. “AI’s Next Frontier: Machines That Understand Language.” Wired, June 24, 2015. https://www.wired.com/2015/06/ais-next-frontier-machines-understand-language/.
Nusca, Andrew. 2011. “Say Command: How Speech Recognition Will Change the World.”
ZDNet, November 2, 2011. https://www.zdnet.com/article/say-command-how-speech-recognition-will-change-the-world/.


