
Malware detection and analysis have been hot topics in cybersecurity research in recent years.
Indeed, the development of obfuscation methods such as packing, for example, need extra caution in order to discover new malware versions.
The standard detection techniques do not always provide tools for interpreting the data.
As a result, we propose a model based on the conversion of binary data into grayscale images, which achieves an 88 percent accuracy rate.
Furthermore, the proposed model has an accuracy of 85 percent in determining whether a sample is packed or encrypted.
It enables us to assess data and take relevant action.
Furthermore, by using attention mechanisms on detection models, we can determine whether parts of the files are suspicious.
This kind of tool should be highly valuable for data analysts since it compensates for the standard detection models' lack of interpretability and may assist to understand why certain harmful files go unnoticed.
Introduction.
The quantity of viruses and assaults has expanded dramatically in recent years.
The amount of online submissions to sandboxes like Virustotal or Any.run, among others, is an example of this phenomena.
Furthermore, owing to sophisticated evasion techniques, these infections are becoming increasingly difficult to detect.
While certain elements of polymorphic malware evolve, its functional aim stays the same.
Signature-based detection becomes outdated as a result of these advancements.
To handle both massive numbers and complicated malware, researchers and businesses have resorted to artificial intelligence methods.
We'll look at static analysis of malware for computational concerns like time and resources in this study.
Dynamic analysis produces excellent findings, but it causes resource issues for firms with thousands of suspicious files to evaluate since a sandbox might take two to three minutes per file.
State of the Art
Malware detection and analysis are burgeoning topics of research.
Several strategies have been presented in this area in recent years.
Signature-based detection is the most widely used detection approach [1,2].
This approach involves storing signatures, which are sections of code from both benign and malicious files.
It involves comparing a suspicious file's signature to a signature database.
This approach has a flaw in that it requires opening the file first, establishing its type, and recording its signature.
Dynamic analysis is another popular and successful strategy.
It tries to execute suspicious files in sandbox settings (physical or virtual) [3].
It permits analysts to examine the file's activity without danger.
This method is very useful for identifying fresh malware or malware that has been altered using obfuscation methods.
However, this approach may be a waste of time and money.
Furthermore, some malware detects virtual environments and does not execute in order to conceal its origin and activity.
Many techniques to static analysis connected with machine learning have been researched in recent works in order to get excellent results in malware detection and overcome signature-based detection and dynamic analysis shortcomings.
The goal of static analysis is to examine a file without executing it in order to determine its purpose and nature.
The most natural method is to extract features based on binary file bit statistics (entropy, distributions, etc.) and then do a binary classification using machine learning techniques (Random Forest, XGBoost, LightGBM for example).
The quality of detection models is influenced by the features used for training and the quantity of data available.
- Anderson et al. [4] provide Ember, a very nice dataset for training machine learning methods.
- Raff et al. [5] on the other hand, analyze bit sequences derived from binary files using Natural Language Processing methods.
Their MalConv approach produces excellent results but needs a significant amount of CPU effort to train.
Furthermore, padding and GAN-based evasion strategies have recently been demonstrated to be particularly sensitive to this strategy.
- To address these flaws, Fleshman et al. [6] created NonNegative MalConv, which lowers the evasion rate without sacrificing accuracy.
- Grayscale photos were used by Nataraj et al. [7] to categorize 25 malware types.
The authors transform binary information to pictures and extract significant characteristics using the GIST technique.
They used these features to train a K-NN and got a percentage of accuracy of 97.25 percent.
This approach, in addition to having a high classification rate, has the advantage of being more resistant to obfuscation, particularly packing, which is the most common obfuscation strategy.
Vu et al. [8] suggested the use of RGB (Red Green Blue) pictures for malware classification using their own transformation approach dubbed Hybrid Image Transformation in continuation of this study (HIT).
They store syntactic information in the green channel of an RGB picture, whereas entropy data is stored in the red and blue channels.
Given the growing interest in picture identification, as seen by ImageNet [9] and performance improvements [10] over the years, several writers suggested employing a Convolutional Neural Network (CNN) to classify malware using binary data transformed to grayscale images.
Rezende [11] used transfer learning on ResNet-50 to classify malware families and obtained a 98.62 percent accuracy rate.
Yakura et al. [12] employed the attention mechanism in conjunction with CNN to highlight spots in grayscale pictures that aid categorization.
They also link important portions of the code to its dismantled function.
Another major area in malware research is the development of detection models that are resistant to obfuscation tactics.
There is a lot of malware out there, but it has been updated to make it invisible.
Polymorphic [13] and metamorphic [14] malicious files, for example, have techniques that seem to change their code but not their behavior.
Malware developers may also change them manually.
- To disturb the detection model without modifying its functions, Kreuk et al. [15] insert bytes directly into the binary file.
- Another change is to include malware, which is one of the most prevalent ways to get beyond antivirus protection.
- Aghakhani et al. [16] provide an outline of the detection methods' limitations in detecting packed malware.
Research Outline
The study's contributions may be summarized as follows:
• A genuine database containing complicated malware gathered in the firm is used to test different detection algorithms.
On our own dataset of binary files, we present detection algorithms that employ grayscale image and HIT preprocessing.
We compare the outcomes of our models to those of models trained using the Ember dataset and preprocessing (LGBM, XGBoost, DNN).
• We present models that account for the possibility of binary data being compressed or encrypted.
One goal of this strategy is to lower the false positive rate caused by certain models' assumption that updated files are always harmful.
Another goal is to equip malware experts with a tool that allows them to learn more about the nature of a suspicious file.
• To understand the outcomes of our image recognition systems, we use attention techniques.
This approach is used to extract the sections of the picture, and therefore the binary, that contributed the most to the classification's score.
This information may then be sent on to security experts to help them reverse engineer the virus more quickly.
Their feedback is then utilized to better understand and fix algorithm flaws.
This work is arranged as follows:
- We describe our dataset and highlight its benefits as well as the various preprocessing techniques used.
- We provide the various models trained using Ember or our own datasets next. The models are compared, and the findings and performances are discussed.
- The next section is devoted to the analysis of changed samples and attention mechanisms, two techniques that might be useful to analysts.
- Lastly we summarize the findings and brings the work to a close.
Dataset and Preprocessing.
Binaries Dataset Description.
There are 22,835 benign and malicious Portable Executable (PE) files in our sample, including packed and encrypted binary files.

The figure above depicts the dataset's precise distribution.
The malware has been gathered in organizations and on sandboxes, and the innocuous files are produced from harvested Windows executables.
The key aspect of this dataset is that the virus is rather tough to detect.
As proof, certain sandboxes and antivirus applications failed to identify them.
Because our dataset comprises complicated and non-generic malware, overfitting should be avoided during model training.
Then utilize the Ember dataset, which contains 600,000 PE files, to train machine learning algorithms, and we evaluate the findings on our own dataset.
We divided the dataset into 80 percent training data, ten percent testing data, and ten percent validation data for the image-based algorithm.
This distribution is the best for keeping a big enough training sample and a complex enough testing sample.
Is the Malware tampered with?
The analysis of packed or encrypted executables, which we refer to as "modified" files in the remainder of the article, is a common challenge when doing static analysis.
Even though many innocuous executables are updated for industrial or intellectual property purposes, artificial intelligence algorithms will frequently label them as harmful.
This is acceptable considering that these operations would substantially affect the executable's entropy and bytes distribution.
Taking into account the changing nature of binary files during the training of detection models is one line of thinking for enhanced performance.
Use of software like ByteHist [17] before the analysis offers a sense of the nature of a file.
Indeed, ByteHist is a program that generates byte-usage histograms for a variety of files, with a concentration on binary executables in the PE format.
ByteHist shows us how bytes are distributed in an executable.
The more compressed the executable, the more uniform the distribution.

Figure above shows unpacked byte distributions of malware and benign code, as well as their UPX-transformed analogues.
As can be seen, UPX alters the byte distribution of binary files, especially in malware cases that have more alterations than the benign file.
It's also a popular packer, thus unpacking binary files made with UPX is simple.
Many malware, on the other hand, contains more complicated software, making analysis more challenging.
Malware Transformation Using Images.
Before we go into how to convert a binary to an image, let's go over why we use images.
First and foremost, when a binary is turned into an image, distinct portions of the binary may be plainly viewed, providing a first direction to an analyst as to where to search, as we shall see in the following section.
The malware writers may then tweak sections of their files or utilize polymorphism to change their signatures or create new versions, as we outlined in the beginning.
Images may record minor changes while maintaining the malware's overall structure.
We immediately transfer a static binary to an array of integers between 0 and 255.
As a result, each binary is translated into a one-dimensional array v [0, 255], which is then reshaped into a two-dimensional array and resized according to the [7] technique.
In other words, the width is governed by the file size.
The entire length of the one-dimensional array divided by the width gives the file's height.
If the width is not divisible by the file size, we rounded up the height and pad zeros.
This approach converts a binary picture to a grayscale image.
The main benefit of this method is that it is extremely quick.
It just takes a few minutes to process 20,000 binaries.
Vu et al. [8] discuss many approaches for converting a binary picture to an RGB image.
Green is the most sensitive to human eyesight and has the greatest coefficient value in picture grayscale conversion, thus their color encoding method is based on it.
They encode syntactic information into the green channel of an RGB picture using their HIT approach, while the red and blue channels collect entropy information.
As a result, clean files will seem to have more green pixels than malicious ones, which have greater entropy and red/blue values.
With picture recognition algorithms, this modification produces excellent results.
The only disadvantage is the time it takes to morph.
The HIT approach takes an average of 25 seconds to convert a binary into a picture.
The grayscale and HIT modifications of the binary file introduced before are shown in Figure below.

Static Methods for Detection.
We examine and evaluate three techniques to malware detection based on static methods and machine learning algorithms in this section:
• First, we use the Ember dataset to train three models, each with its unique feature extraction strategy.
• We next propose a CNN and three hybrid models to identify malware utilizing these temporal grayscale pictures as input.
• Finally, we use the HIT approach to train another CNN on an RGB picture.
Binary Files Algorithms.
We will evaluate three methods for static analysis:
- XGBoost,
- LightGBM,
- and a deep neural network (DNN).
XGBoost [18] is a well-known data-testing technique, but it might take a long time to run on a big dataset.
As a result, we compare it to LightBGM [19], which Ember uses in conjunction with their dataset.
Let's take a brief look at the LightGBM algorithm, which is currently relatively unknown.
It employs a revolutionary approach known as Gradient-based One-Side Sampling (GOSS) to filter out data instances in order to get a split value, while XGBoost use a pre-sorted algorithm and a histogram-based algorithm to determine the optimal split.
In this case, examples are observations.
• Faster training speed and greater efficiency as compared to other algorithms such as Random Forest or XGBoost.
• Improved accuracy using a more complicated tree (replaces continuous values with discrete bins, resulting in reduced memory consumption).
If we concentrate on it in this research, it is mostly because of its ability to manage large amounts of data.
When compared to XGBoost, it can handle huge datasets just as effectively and takes much less time to train.
To begin, we train the XGBoost and LightGBM algorithms on the Ember dataset and then put them to the test on our own data.
In addition, we train a DNN on the Ember learning dataset since this kind of model works well with a huge dataset with a lot of characteristics.
To compare models, we utilize the F1 score and the accuracy score.
The table below summarizes the findings.

The performances of LightGBM and DNN are relatively similar in this table, while XGBoost is less efficient (either in precision or computing time).
Grayscale Image Algorithms.
We convert our dataset into grayscale photos and use them to train CNN based on the work of Nataraj et al. [7].
Three convolutional layers, a dense layer with a ReLU activation function, and a sigmoid function for binary scoring make up our CNN.
In addition, we propose hybrid models integrating CNN with LightGBM, RF, or Support Vector Machine, as inspired by [20]. (SVM).
To begin, we utilize CNN to minimize the number of dimensions, reducing each binary picture from 4,096 to 256 features.
The RF, LightGBM, and SVM models are then trained using these 256 additional features.
F1 and accuracy ratings are still utilized to compare models, as seen in the Table.
The hybrid model combining CNN and RF beats the four grayscale models, as can be observed, although the results are close overall.
Furthermore, the results are comparable to those of the LightGBM and DNN described in Sect. 3.1.
It's worth noting that the grayscale models are trained using just 19,400 binary data, compared to 600,000 binary files for the prior models.
In comparison to conventional models and preprocessing, our grayscale models remain reliable for malware detection with the grayscale transformation and a dataset thirty times smaller.
RGB Image Algorithms.
We are now assessing our CNN utilizing RGB photos and HIT transformation.
F1 and accuracy scores on the test sample are shown in Table.
Even though the RGB model outperforms the others previously discussed, training on a local system using RGB photos takes a long time, while scoring on a single one is quick.
Because of the complexity of the HIT technique, converting binary to pictures takes a lengthy time, on average 25 seconds per sample, compared to less than one second for grayscale conversions.
To begin with, adding the time it takes to convert the 24,000 samples significantly lengthens the learning process.
Furthermore, the score is received in less than one second when predicting malware, but the time for transforming the binary into an image is added.
Given this, using HIT transformation instead of grayscale transformation in a corporate setting is pointless, which is why we will not focus on training additional models using HIT preprocessing.
Attention Mechanism and Modified Binary Analysis.
Aside from obtaining the most accurate findings possible, the goal is to make them useable by an analyst.
To do so, we need to understand why our algorithms offer high or low ratings.
This not only helps us to better the learning process in the event of a mistake, but it also allows analysts to know where to look.
To make malware easier to comprehend and analyze, we offer two approaches: • The first technique is to utilize knowledge about the nature of binary files to train our algorithms.
We know whether the training set's binary files have been changed in particular.
The goal is to limit the number of false positives produced by these two obfuscation approaches while simultaneously providing additional information about the new suspicious files.
The use of an attention mechanism on model trains with grayscale images is the second approach.
To detect suspicious patterns, we can create a heatmap using the attention mechanism.
Furthermore, the heatmap aids in comprehending the malware detection model's results.
Binaries that have been modified.
We also give two models that are trained while taking into consideration the changed nature of the binary file in order to lower the false positive rate due to obfuscation.
Both models utilize grayscale photographs as their input.
1. The first model is a CNN that outputs information on the binary file's nature, whether it is malware or not, and whether it is obfuscated or not.
We now have double knowledge of the binary file's attributes thanks to a single CNN.
The F1 score for this model is 0.8924, and the accuracy score is 0.8852.
2. The second model is a three-CNN superposition.
The first is used to distinguish binary files with an accuracy of 85 percent based on whether they are obfuscated or not.
The two others are used to determine if a binary file is malicious or benign, and each model is trained on changed and unmodified binary files, respectively.
The key benefit of this approach is that each CNN may be retrained independently from the other two.
They also employ various architectures in order to improve the generalization of the data they use to train them.
This model has an F1 score of 0.8797 and an accuracy score of 0.8699.
As can be seen, the first model performs better than the second.
It can also tell whether a binary file has been edited with an accuracy rating of 84%.
This information might aid malware analysts in improving their knowledge.
This may explain why some innocuous files are mistakenly identified as malware.
Furthermore, if certain suspicious files are modified and the result of malware detection is ambiguous, it may encourage the use of sandboxes.
Results Interpretability and Most Important Bytes
We provide a strategy in this part that may assist analysts in interpreting the findings of detection models based on the conversion of binary data into grayscale pictures.
Depending on the relevant portions of the file, a grayscale picture representation of an executable has different texture [21].
We can extract information from the binary using tools like PE file and observe the connection between the PE file and its grayscale visual representation.
The figure displays an executable converted to an image, the PE file's matching sections (left), and information about each texture (right).

The connections between the PE file and the grayscale picture might help an analyst rapidly see the binary file's regions of interest.
To proceed with the investigation, it will be important to determine which elements of the picture contributed to the malware detection algorithm's conclusions.
To achieve so, we use attenuation techniques, which consist of emphasizing the pixels that have the most impact on our algorithm's prediction score.
With our own CNN provided in Sect. 3.2, we employ GradCAM++ [22].
The GradeCAM++ method retrieves the pixels that have the most effect on the model's conclusion, i.e. those that indicate whether the file is benign or malicious, from the CNN.
It produces a heatmap, which may be read as follows: the warmer the coloring, the more the picture region influences the CNN prediction.
Heatmaps of the four binaries described in Sect. 2.2 are shown in Figure below.
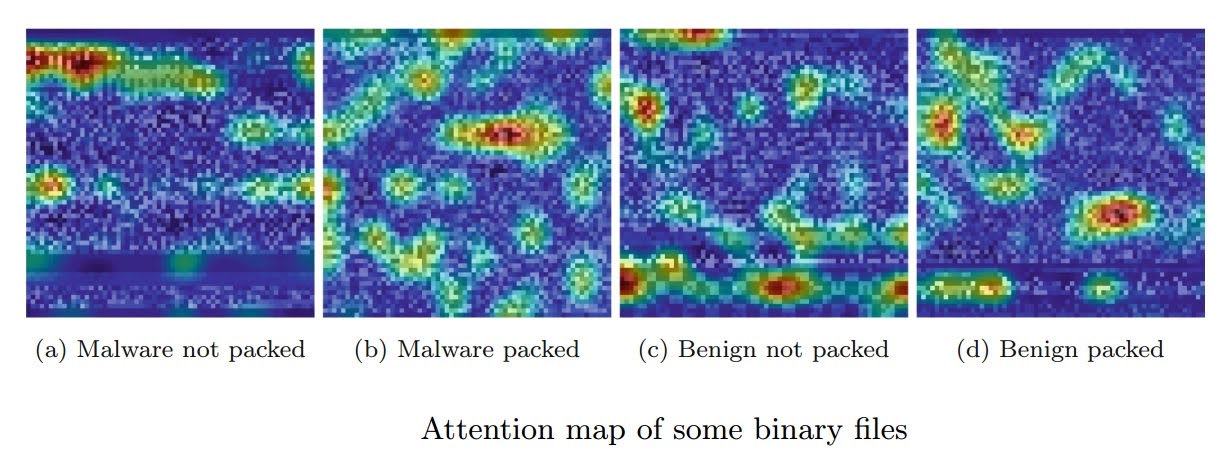
We see that the virus and its compressed form have different activation zones.
We can say the same thing about the good.
In addition, since the packed malware's byte distribution has been drastically modified, we find that more zones and pixels are lighted up than in the original infection.
This indicates that the model requires more data to make a decision.
On the other hand, this kind of representation could be useful in figuring out why a binary file has been misclassified.
Padding, for example, is a typical evasion tactic that involves adding byte sequences to a file to artificially expand its size and deceive the antivirus.
This kind of method is readily detectable via picture representation.

However, as shown in Figure above, the padding zone is considered a significant portion of the file in both situations.
The innocuous file is misclassified and branded as malware, even though the virus is successfully discovered.
As a result, padding is seen as a malevolent criterion.
This information might be used to improve the malware detection model's performance.
The activation map on binary file images appears to be a fun and useful tool for malware researchers.
To fully maximize the promise of this method, however, further research is required.
Indeed, we demonstrate the usage of heatmap for binary file packing and padding analysis, but there are other alternative obfuscation approaches.
We also concentrate on malware and benign pictures here, but an expansion of this technique will be to extract code straight from the binary file based on the hot zone of the associated heatmap.
Results and conclusion
Let us begin by summarizing the findings before concluding this paper.
Indeed, CNN trained on RGB pictures using HIT produces superior results.
The transformation time, on the other hand, is much too crucial to give an effective approach for industrial deployment.
The DNN and LightGBM models then exhibit the Ember dataset's predicted efficacy.
Our models are marginally less efficient than theirs since they utilize grayscale photographs as input.
However, the findings are equivalent to a thirty-fold smaller training sample.
Finally, the two models were trained on grayscale photographs with information on whether the original binary file had been modified or not, indicating that this approach may be used to identify malware.
They also provide you more information about binary files than standard detection models.
The CNN algorithm, when combined with RF, LGBM, and SVM, has promising detection potential.
In future study, we'll concentrate on determining the capacity or limit of these models.
In this post, we've discussed many techniques of detecting static malware.
The processing time needed for dynamic malware analysis in a sandbox is a recurrent issue in many businesses.
However, we know that in certain cases, customized malware is the only option.
We make no claim to be able to replace this analysis; rather, we provide an overlay.
Our algorithms allow us to swiftly evaluate a vast volume of malware and decide whether ones are harmful or not, while also moderating the outcome based on whether the binary is updated or not.
This will enable us to do dynamic analysis solely on those binaries, saving time and resources.
Furthermore, analyzing the image's most essential pixels and regions might reveal valuable information to analysts.
By specifying where to hunt for the questionable binary, they may save time in the deeper investigation.
We will focus on attention processes in future research.
The goal is to link the regions of relevance, as determined by attention mechanisms, with the harmful code connected with them to aid analysts in their job.
We wish to apply reinforcement learning to understand and prevent malware evasion strategies, on the other hand.
Find Jai on Twitter | LinkedIn | Instagram
You may also want to read and learn more Cyber Security Systems here.
You may also want to read more about Artificial Intelligence here.
References And Further Reading
1. Sung, A.H., Xu, J., Chavez, P., Mukkamala, S.: Static analyzer of vicious executables. In: 20th Annual Computer Security Applications Conference, pp. 326–334. IEEE (2004)
2. Sathyanarayan, V.S., Kohli, P., Bruhadeshwar, B.: Signature generation and detection of malware families. In: Australasian Conference on Information Security and Privacy, pp. 336–349. Springer (2008)
3. Vasilescu, M., Gheorghe, L., Tapus, N.: Practical malware analysis based on sandboxing. In: Proceedings - RoEduNet IEEE International Conference, pp. 7–12 (2014)
4. Anderson, H.S., Roth, P.: Ember: an open dataset for training static PE malware machine learning models. arXiv preprint arXiv:1804.04637 (2018)
5. Raff, E., Barker, J., Sylvester, J., Brandon, R., Catanzaro, B., Nicholas, C.K.: Malware detection by eating a whole exe. arXiv preprint arXiv:1710.09435 (2017)
6. Fleshman, W., Raff, E., Sylvester, J., Forsyth, S., McLean, M.: Non-negative networks against adversarial attacks. arXiv preprint arXiv:1806.06108 (2018)
7. Nataraj, L., Karthikeyan, S., Jacob, G., Manjunath, B.S.: Malware images: visualization and automatic classification. In: Proceedings of the 8th International Symposium on Visualization for Cyber Security, pp. 1–7 (2011)
8. Vu, D.L., Nguyen, T.K., Nguyen, T.V., Nguyen, T.N., Massacci, F., Phung, P.H.: A convolutional transformation network for malware classification. In: 2019 6th NAFOSTED Conference on Information and Computer Science (NICS), pp. 234–239. IEEE (2019)
9. Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255. IEEE (2009)
10. Alom, M.Z., et al.: The history began from alexnet: a comprehensive survey on deep learning approaches. arXiv preprint arXiv:1803.01164 (2018)
11. Rezende, E., Ruppert, G., Carvalho, T., Ramos, F., De Geus, P.: Malicious software classification using transfer learning of resnet-50 deep neural network. In: 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), pp. 1011–1014. IEEE (2017)
12. Yakura, H., Shinozaki, S., Nishimura, R., Oyama, Y., Sakuma, J.: Malware analysis of imaged binary samples by convolutional neural network with attention mechanism. In: Proceedings of the Eighth ACM Conference on Data and Application Security and Privacy, pp. 127–134 (2018)
13. Sharma, A., Sahay, S.K.: Evolution and detection of polymorphic and metamorphic malwares: a survey. Int. J. Comput. Appl. 90(2), 7–11 (2014)
14. Zhang, Qinghua, Reeves, Douglas S.: MetaAware: identifying metamorphic malware. In: Proceedings - Annual Computer Security Applications Conference, ACSAC, pp. 411–420 2007 (2008)
15. Kreuk, F., Barak, A., Aviv-Reuven, S., Baruch, M., Pinkas, B., Keshet, J.: Adversarial examples on discrete sequences for beating whole-binary malware detection. arXiv preprint arXiv:1802.04528, pp. 490–510 (2018)
16. Aghakhani, H.: When malware is packin’heat; limits of machine learning classifiers based on static analysis features. In: Network and Distributed Systems Security (NDSS) Symposium 2020 (2020)
17. Christian Wojner. Bytehist. https://www.cert.at/en/downloads/software/software-bytehist
18. Chen, T., Guestrin, C.: Xgboost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 785–794 (2016)
19. Ke, G.: Lightgbm: a highly efficient gradient boosting decision tree. In: Advances in Neural Information Processing Systems, vol. 30, pp. 3146–3154 (2017)
20. Xiao, Y., Xing, C., Zhang, T., Zhao, Z.: An intrusion detection model based on feature reduction and convolutional neural networks. IEEE Access 7, 42210–42219 (2019)
21. Conti, G., et al.: A visual study of primitive binary fragment types. Black Hat USA, pp. 1–17 (2010)
22. Chattopadhay, A., Sarkar, A., Howlader, P., Balasubramanian, V.N.: GradCAM++: generalized gradient-based visual explanations for deep convolutional networks. In: 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 839–847. IEEE (2018)


