Machine translation is the process of using computer technology to automatically translate human languages.
The US administration saw machine translation as a valuable
instrument in diplomatic attempts to restrict communism in the USSR and the
People's Republic of China from the 1950s through the 1970s.
Machine translation has lately become a tool for marketing
goods and services in countries where they would otherwise be unavailable due
to language limitations, as well as a standalone offering.
Machine translation is also one of the litmus tests for
artificial intelligence progress.
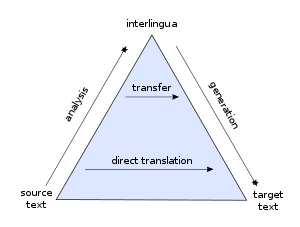
This artificial intelligence study advances along three
broad paradigms.
Rule-based expert systems and statistical methods to machine
translation are the earliest.
Neural-based machine translation and example-based machine
translation are two more contemporary paradigms (or translation by analogy).
Within computer linguistics, automated language translation
is now regarded an academic specialization.
While there are multiple possible roots for the present discipline of machine translation, the notion of automated translation as an academic topic derives from a 1947 communication between crystallographer Andrew D. Booth of Birkbeck College (London) and Warren Weaver of the Rockefeller Foundation.
"I have a manuscript in front of me that is written in
Russian, but I am going to assume that it is truly written in English and that
it has been coded in some bizarre symbols," Weaver said in a preserved
note to colleagues in 1949.
To access the information contained in the text, all I have to do is peel away the code" (Warren Weaver, as cited in Arnold et al. 1994, 13).
Most commercial machine translation systems have a
translation engine at their core.
The user's sentences are parsed several times by translation
engines, each time applying algorithmic rules to transform the source sentence
into the desired target language.
There are rules for word-based and phrase-based trans
formation.
The initial objective of a parser software is generally to
replace words using a two-language dictionary.
Additional processing rounds of the phrases use comparative
grammatical rules that consider sentence structure, verb form, and suffixes.
The intelligibility and accuracy of translation engines are
measured.
Machine translation isn't perfect.
Poor grammar in the source text, lexical and structural
differences between languages, ambiguous usage, multiple meanings of words and
idioms, and local variations in usage can all lead to "word salad"
translations.
In 1959–60, MIT philosopher, linguist, and mathematician
Yehoshua Bar-Hillel issued the harshest early criticism of machine translation
of language.
In principle, according to Bar-Hillel, near-perfect machine
translation is impossible.
He used the following sentence to demonstrate the issue:
John was on the prowl for his toy box.
He eventually discovered it.
In the pen, there was a box.
John was overjoyed.
The word "pen" poses a problem in this statement
since it might refer to a child's playpen or a writing ballpoint pen.
Knowing the difference necessitates a broad understanding of
the world, which a computer lacks.
When the National Academy of Sciences Automatic Language
Processing Advisory Committee (ALPAC) released an extremely damaging report
about the poor quality and high cost of machine translation in 1964, the
initial rounds of US government funding eroded.
ALPAC came to the conclusion that the country already had an
abundant supply of human translators capable of producing significantly greater
translations.
Many machine translation experts slammed the ALPAC report,
pointing to machine efficiency in the preparation of first drafts and the
successful rollout of a few machine translation systems.
In the 1960s and 1970s, there were only a few machine
translation research groups.
The TAUM group in Canada, the Mel'cuk and Apresian groups in
the Soviet Union, the GETA group in France, and the German Saarbrücken SUSY
group were among the biggest.
SYSTRAN (System Translation), a private corporation financed
by government contracts founded by Hungarian-born linguist and computer
scientist Peter Toma, was the main supplier of automated translation technology
and services in the United States.
In the 1950s, Toma became interested in machine translation
while studying at the California Institute of Technology.
Around 1960, Toma moved to Georgetown University and started
collaborating with other machine translation experts.
The Georgetown machine translation project, as well as
SYSTRAN's initial contract with the United States Air Force in 1969, were both
devoted to translating Russian into English.
That same year, at Wright-Patterson Air Force Base, the
company's first machine translation programs were tested.
SYSTRAN software was used by the National Aeronautics and
Space Administration (NASA) as a translation help during the Apollo-Soyuz Test
Project in 1974 and 1975.
Shortly after, SYSTRAN was awarded a contract by the
Commission of the European Communities to offer automated translation services,
and the company has subsequently amalgamated with the European Commission (EC).
By the 1990s, the EC had seventeen different machine
translation systems focused on different language pairs in use for internal
communications.
In 1992, SYSTRAN began migrating its mainframe software to
personal computers.
SYSTRAN Professional Premium for Windows was launched in
1995 by the company.
SYSTRAN continues to be the industry leader in machine
translation.
METEO, which has been in use by the Canadian Meteorological
Center in Montreal since 1977 for the purpose of translating weather bulletins
from English to French; ALPS, developed by Brigham Young University for Bible
translation; SPANAM, the Pan American Health Organization's Spanish-to-English
automatic translation system; and METAL, developed at the University of
Toronto.
In the late 1990s, machine translation became more readily
accessible to the general public through web browsers.
Babel Fish, a web-based application created by a group of
researchers at Digital Equipment Corporation using SYSTRAN machine translation
technology, was one of the earliest online language translation services (DEC).
Thirty-six translation pairs between thirteen languages were
supported by the technology.
Babel Fish began as an AltaVista web search engine tool
before being sold to Yahoo! and then Microsoft.
The majority of online translation services still use
rule-based and statistical machine translation.
Around 2016, SYSTRAN, Microsoft Translator, and Google
Translate made the switch to neural machine translation.
103 languages are supported by Google Translate.
Predictive deep learning algorithms, artificial neural
networks, or connectionist systems based after biological brains are used in
neural machine translation.
Machine translation based on neural networks is achieved in
two steps.
The translation engine models its interpretation in the
first phase based on the context of each source word within the entire
sentence.
The artificial neural network then translates the entire
word model into the target language in the second phase.
Simply said, the engine predicts the probability of word
sequences and combinations inside whole sentences, resulting in a fully
integrated translation model.
The underlying algorithms use statistical models to learn
language rules.
The Harvard SEAS natural language processing group, in
collaboration with SYSTRAN, has launched OpenNMT, an open-source neural machine
translation system.
You may also want to read more about Artificial Intelligence here.
See also:
Cheng, Lili; Natural Language Processing and Speech Understanding.
Further Reading:
Arnold, Doug J., Lorna Balkan, R. Lee Humphreys, Seity Meijer, and Louisa Sadler. 1994. Machine Translation: An Introductory Guide. Manchester and Oxford: NCC Blackwell.
Bar-Hillel, Yehoshua. 1960. “The Present Status of Automatic Translation of Languages.” Advances in Computers 1: 91–163.
Garvin, Paul L. 1967. “Machine Translation: Fact or Fancy?” Datamation 13, no. 4: 29–31.
Hutchins, W. John, ed. 2000. Early Years in Machine Translation: Memoirs and Biographies of Pioneers. Philadelphia: John Benjamins.
Locke, William Nash, and Andrew Donald Booth, eds. 1955. Machine Translation of Languages. New York: Wiley.
Yngve, Victor H. 1964. “Implications of Mechanical Translation Research.” Proceedings of the American Philosophical Society 108 (August): 275–81.