Artificial intelligence and quantum computing, according to Johannes Otterbach, a physicist at Rigetti Computing in Berkeley, California, are natural friends since both technologies are essentially statistical.
Airbus, Atos, Baidu, b|eit, Cambridge Quantum Computing,
Elyah, Hewlett-Packard (HP), IBM, Microsoft Research QuArC, QC Ware, Quantum
Benchmark Inc., R QUANTECH, Rahko, and Zapata Computing are among the
organizations that have relocated to the region.
Bits are used to encode and modify data in traditional
general-purpose computer systems.
Bits may only be in one of two states: 0 or 1.
Quantum computers use the actions of subatomic particles
like electrons and photons to process data.
Superposition—particles residing in all conceivable states
at the same time—and entanglement—the pairing and connection of particles such
that they cannot be characterized independently of the state of others, even at
long distances—are two of the most essential phenomena used by quantum computers.
Such entanglement was dubbed "spooky activity at a
distance" by Albert Einstein.
Quantum computers use quantum registers, which are made up
of a number of quantum bits or qubits, to store data.
While a clear explanation is elusive, qubits might be
understood to reside in a weighted combination of two states at the same time
to yield many states.
Each qubit that is added to the system doubles the
processing capability of the system.
More than one quadrillion classical bits might be processed
by a quantum computer with just fifty entangled qubits.
In a single year, sixty qubits could carry all of humanity's
data.
Three hundred qubits might compactly encapsulate a quantity
of data comparable to the observable universe's classical information content.
Quantum computers can operate in parallel on large
quantities of distinct computations, collections of data, or operations.
True autonomous transportation would be possible if a
working artificially intelligent quantum computer could monitor and manage all
of a city's traffic in real time.
By comparing all of the photographs to the reference photo
at the same time, quantum artificial intelligence may rapidly match a single
face to a library of billions of photos.
Our understanding of processing, programming, and complexity
has radically changed with the development of quantum computing.
A series of quantum state transformations is followed by a
measurement in most quantum algorithms.
The notion of quantum computing goes back to the 1980s, when
physicists such as Yuri Manin, Richard Feynman, and David Deutsch realized that
by using so-called quantum gates, a concept taken from linear algebra,
researchers would be able to manipulate information.
They hypothesized qubits might be controlled by different
superpositions and entanglements into quantum algorithms, the outcomes of which
could be observed, by mixing many kinds of quantum gates into circuits.
Some quantum mechanical processes could not be efficiently
replicated on conventional computers, which presented a problem to these early
researchers.
They thought that quantum technology (perhaps included in a
universal quantum Turing computer) would enable quantum simulations.
In 1993, Umesh Vazirani and Ethan Bernstein of the
University of California, Berkeley, hypothesized that quantum computing will
one day be able to effectively solve certain problems quicker than traditional
digital computers, in violation of the extended Church-Turing thesis.
In computational complexity theory, Vazirani and Bernstein
argue for a special class of bounded-error quantum polynomial time choice
problems.
These are issues that a quantum computer can solve in
polynomial time with a one-third error probability in most cases.
The frequently proposed threshold for Quantum Supremacy is
fifty qubits, the point at which quantum computers would be able to tackle
problems that would be impossible to solve on conventional machines.
Although no one believes quantum computing would be capable
of solving all NP-hard issues, quantum AI researchers think the machines will
be capable of solving specific types of NP intermediate problems.
Creating quantum machine algorithms that do valuable work
has proved to be a tough task.
In 1994, AT&T Laboratories' Peter Shor devised a
polynomial time quantum algorithm that beat conventional methods in factoring
big numbers, possibly allowing for the speedy breakage of current kinds of
public key encryption.
Since then, intelligence services have been stockpiling
encrypted material passed across networks in the hopes that quantum computers
would be able to decipher it.
Another technique devised by Shor's AT&T Labs colleague
Lov Grover allows for quick searches of unsorted datasets.
Quantum neural networks are similar to conventional neural
networks in that they label input, identify patterns, and learn from experience
using layers of millions or billions of linked neurons.
Large matrices and vectors produced by neural networks can
be processed exponentially quicker by quantum computers than by classical
computers.
Aram Harrow of MIT and Avinatan Hassidum gave the critical
algorithmic insight for rapid classification and quantum inversion of the
matrix in 2008.
Michael Hartmann, a visiting researcher at Google AI Quantum
and Associate Professor of Photonics and Quantum Sciences at Heriot-Watt
University, is working on a quantum neural network computer.
Hartmann's Neuromorphic Quantum Computing (Quromorphic)
Project employs superconducting electrical circuits as hardware.
Hartmann's artificial neural network computers are inspired
by the brain's neuronal organization.
They are usually stored in software, with each artificial
neuron being programmed and connected to a larger network of neurons.
Hardware that incorporates artificial neural networks is
also possible.
Hartmann estimates that a workable quantum computing
artificial intelligence might take 10 years to develop.
D-Wave, situated in Vancouver, British Columbia, was the
first business to mass-produce quantum computers in commercial numbers.
In 2011, D-Wave started producing annealing quantum
computers.
Annealing processors are special-purpose products used for a
restricted set of problems with multiple local minima in a discrete search
space, such as combinatorial optimization issues.
The D-Wave computer isn't polynomially equal to a universal
quantum computer, hence it can't run Shor's algorithm.
Lockheed Martin, the University of Southern California,
Google, NASA, and the Los Alamos National Laboratory are among the company's
clients.
Universal quantum computers are being pursued by Google,
Intel, Rigetti, and IBM.
Each one has a quantum processor with fifty qubits.
In 2018, the Google AI Quantum lab, led by Hartmut Neven,
announced the introduction of their newest 72-qubit Bristlecone processor.
Intel also debuted its 49-qubit Tangle Lake CPU last year.
The Aspen-1 processor from Rigetti Computing has sixteen
qubits.
The IBM Q Experience quantum computing facility is situated
in Yorktown Heights, New York, inside the Thomas J.
Watson Research Center.
To create quantum commercial applications, IBM is
collaborating with a number of corporations, including Honda, JPMorgan Chase,
and Samsung.
The public is also welcome to submit experiments to be
processed on the company's quantum computers.
Quantum AI research is also highly funded by government
organizations and universities.
The NASA Quantum Artificial Intelligence Laboratory (QuAIL)
has a D-Wave 2000Q quantum computer with 2,048 qubits that it wants to use to
tackle NP-hard problems in data processing, anomaly detection and
decision-making, air traffic management, and mission planning and coordination.
The NASA team has chosen to concentrate on the most
difficult machine learning challenges, such as generative models in
unsupervised learning, in order to illustrate the technology's full potential.
In order to maximize the value of D-Wave resources and
skills, NASA researchers have opted to focus on hybrid quantum-classical
techniques.
Many laboratories across the globe are investigating
completely quantum machine learning.
Quantum Learning Theory proposes that quantum algorithms
might be utilized to address machine learning problems, hence improving
traditional machine learning techniques.
Classical binary data sets are supplied into a quantum
computer for processing in quantum learning theory.
The NIST Joint Quantum Institute and the University of
Maryland's Joint Center for Quantum Information and Computer Science are also
bridging the gap between machine learning and quantum computing.
Workshops bringing together professionals in mathematics,
computer science, and physics to use artificial intelligence algorithms in
quantum system control are hosted by the NIST-UMD.
Engineers are also encouraged to employ quantum computing to
boost the performance of machine learning algorithms as part of the alliance.
The Quantum Algorithm Zoo, a collection of all known quantum
algorithms, is likewise housed at NIST.
Scott Aaronson is the director of the University of Texas at
Austin's Quantum Information Center.
The department of computer science, the department of
electrical and computer engineering, the department of physics, and the
Advanced Research Laboratories have collaborated to create the center.
The University of Toronto has a quantum machine learning
start-up incubator.
Peter Wittek is the head of the Quantum Machine Learning
Program of the Creative Destruction Lab, which houses the QML incubator.
Materials discovery, optimization, and logistics,
reinforcement and unsupervised machine learning, chemical engineering, genomics
and drug discovery, systems design, finance, and security are all areas where
the University of Toronto incubator is fostering innovation.
In December 2018, President Donald Trump signed the National
Quantum Initiative Act into law.
The legislation establishes a partnership of the National
Institute of Standards and Technology (NIST), the National Science Foundation
(NSF), and the Department of Energy (DOE) for quantum information science
research, commercial development, and education.
The statute anticipates the NSF and DOE establishing many
competitively awarded research centers as a result of the endeavor.
Due to the difficulties of running quantum processing units
(QPUs), which must be maintained in a vacuum at temperatures near to absolute
zero, no quantum computer has yet outperformed a state-of-the-art classical
computer on a challenging job.
Because quantum computing is susceptible to external
environmental impacts, such isolation is required.
Qubits are delicate; a typical quantum bit can only exhibit
coherence for ninety microseconds before degrading and becoming unreliable.
In an isolated quantum processor with high thermal noise,
communicating inputs and outputs and collecting measurements is a severe
technical difficulty that has yet to be fully handled.
The findings are not totally dependable in a classical sense
since the measurement is quantum and hence probabilistic.
Only one of the quantum parallel threads may be randomly
accessed for results.
During the measuring procedure, all other threads are
deleted.
It is believed that by connecting quantum processors to
error-correcting artificial intelligence algorithms, the defect rate of these
computers would be lowered.
Many machine intelligence applications, such as deep
learning and probabilistic programming, rely on sampling from high-dimensional
probability distributions.
Quantum sampling methods have the potential to make
calculations on otherwise intractable issues quicker and more efficient.
Shor's method employs an artificial intelligence approach
that alters the quantum state in such a manner that common properties of output
values, such as symmetry of period of functions, can be quantified.
Grover's search method manipulates the quantum state using
an amplification technique to increase the possibility that the desired output
will be read off.
Quantum computers would also be able to execute many AI
algorithms at the same time.
Quantum computing simulations have recently been used by
scientists to examine the beginnings of biological life.
Unai Alvarez-Rodriguez of the University of the Basque
Country in Spain built so-called artificial quantum living forms using IBM's QX
superconducting quantum computer.
Find Jai on Twitter | LinkedIn | Instagram
You may also want to read more about Artificial Intelligence here.
See also:
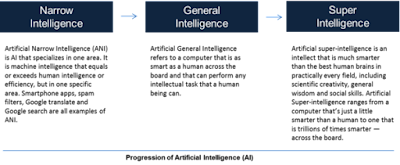
General and Narrow AI.
References & Further Reading:
Aaronson, Scott. 2013. Quantum Computing Since Democritus. Cambridge, UK: Cambridge University Press.
Biamonte, Jacob, Peter Wittek, Nicola Pancotti, Patrick Rebentrost, Nathan Wiebe, and Seth Lloyd. 2018. “Quantum Machine Learning.” https://arxiv.org/pdf/1611.09347.pdf.
Perdomo-Ortiz, Alejandro, Marcello Benedetti, John Realpe-Gómez, and Rupak Biswas. 2018. “Opportunities and Challenges for Quantum-Assisted Machine Learning in Near-Term Quantum Computers.” Quantum Science and Technology 3: 1–13.
Schuld, Maria, Ilya Sinayskiy, and Francesco Petruccione. 2015. “An Introduction to Quantum Machine Learning.” Contemporary Physics 56, no. 2: 172–85.
Wittek, Peter. 2014. Quantum Machine Learning: What Quantum Computing Means to Data Mining. Cambridge, MA: Academic Press